

HashMap的结构和实现原理
HashMap是我们常用的数据结构,由数组和链表组合构成,在java8后,链表长度大于8时,链表会转成红黑树,链表长度小于6时,会由红黑树转为链表。
用一张图简单体现:
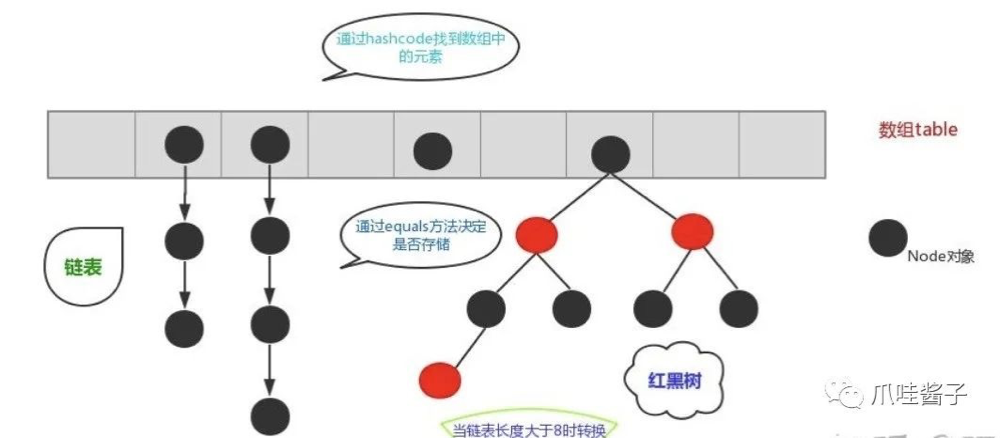
数组里每个地方都存了key-value这样的实例,在put操作的时候会根据key的hash值去计算index(即在数组中的位置)
ps:这里key的hash值是将hashcode高低十六位异或过的,源码如下

我们都知道数组的长度是有限的,在有限的长度里我们使用哈希,哈希本身就存在概率性,如果两个key的hash值是相同的,即发生hash碰撞,就会形成链表。
-
什么是hash碰撞(hash冲突)?
在解释hash碰撞之前首先简单了解hash算法和hash表。
hash算法:就是把输入的值通过散列算法计算得出一个散列值。
hash表:又叫做“散列表”,它是通过key直接访问到内存存储位置的数据结构,在具体实现上,我们通过hash函数把key映射到表中某个位置,来获取这个位置的数据,从而加快数据的查找。
在计算hash地址的过程中会出现对于不同的关键字出现相同的哈希地址的情况,即key1 ≠ key2,但是f(key1) = f(key2),这种情况就是Hash 碰撞
-
如何解决hash碰撞?
1、开放地址法:也称为线性探测法,就是从发生冲突的位置开始,按照一定次序(顺延)从hash表找到一个空闲位置,把发生冲突的元素存到这个位置。ThreadLocal就是用这种方法解决hash碰撞。
2、链地址法:就是把冲突的key,以单向链表来进行存储,比如HashMap
3、再哈希法:就是存在冲突的时候,再hash,一只运算知道不再产生冲突
-
HashMap是如何解决hash碰撞的?
在java8中是通过链地址法以及红黑树解决,其中红黑树是为了优化hash表的链表过长导致时间复杂度增加的问题。
-
如何控制hash碰撞的概率?
好的hash算法和扩容机制
HashMap在java1.8和java1.7中有什么区别
- 结构不同
-
插入方式不同
java1.7采用的是头插法,java8采用的是尾插法。
java1.7先扩容在插入数据,java1.8是先插入数据后扩容
扩容时java1.7需要rehash,在java1.8中不需要重新计算hash值。
HashMap的扩容机制
-
何时扩容
1、数组为空时即tab==null 或者tab.length==0
2、元素个数超过数组长度*负载因子的时候,load_factor:负载因子,默认值0.75,DEFAULT_INITIAL_CAPACITY:初始容量,1<<4即16
3、当链表长度大于8且数组长度小于64时
-
如何扩容
先创建一个新的Entry空数组,长度是原数组的2倍,遍历原Entry数组。
如果oldTab[i]只有一条数据,没有形成链表,那么直接按照公式存放数据
-
为什么扩容是2的次幂
HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
put操作如何实现的?
put操作具体实现可以通过下图来理解,有兴趣可以结合流程图看源码可以更清楚
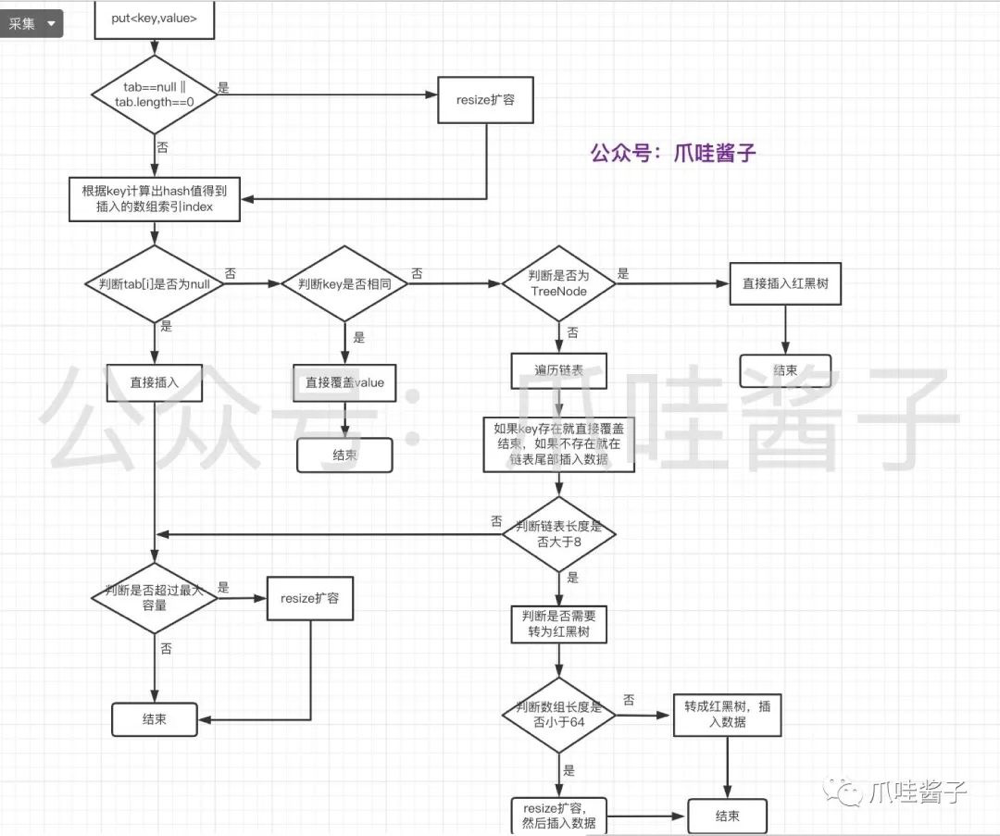
put操作需要注意的点:
HashMap的并发问题
-
HashMap是线程安全的么?
HashMap是线程不安全的。
-
为什么说HashMap是线程不安全的?
死循环、数据丢失:java7以前HashMap采用头插法,多线程扩容就会引起链表顺序倒置,形成死循环,数据丢失,java8改成尾插法后,死循环和数据丢失的问题已经解决。
数据覆盖:HashMap在执行put操作时,因为没有加同步锁,多线程put可能会导致数据覆盖
-
如何解决HashMap线程不安全的问题?
一般我们会使用ConcurrentHashMap或者HashTable
1、HashTable是直接在方法上加锁(即用synchronized关键字修饰方法),简单粗暴,效率低不推荐。
2、使用Collections.synchronizedMap(new HashMap()),这个方法返回一个SynchronizedMap,该内部类中维护了一个普通的map和一个对象排斥锁mutex。如果我们在构造方法中传入了mutex,就使用我们传入的互斥锁,如果没有传入,就是用当前的对象锁。然后在方法上,全部加上synchronized,类似于HashTable
3、ConcurrentHashMap效率相对高一些。所以存在线程不安全的场景我们都使用的是ConcurrentHashMap。由于内容太多具体实现后面我会单独写一篇介绍,在这就不多介绍。
一般用什么作为HashMap的key
-
key可以为null么?
可以。
-
一般用什么作为HashMap的key?
一般用Integer,String这种不可变类作为key,String 最为常用,如果用可变类作为key,它的hashcode可能会发生改变,导致put进去的值无法get出